هالوسینیشن یا توهم هوش مصنوعی چیست؟ + ۶ راهکار برای پژوهشگران و دانشجویان
خطای هالوسینیشن هوش مصنوعی چیست؟
حتما براتون پیش اومده که دستور یا پرامپتی رو به مدل هوش مصنوعی دادید و در جواب مدل هوش مصنوعی، خروجی رو براتون تولید کرده که درست نبوده، این خروجی نادرست تولیدی با مدل LLM رو به عنوان خطای هالوسنیشن یا تولید محتوای ساختگی هوش مصنوعی میشناسن. ما در این مقاله دلایل ایجاد خطا و راهکارهای رفع اون رو به ویژه در نگارش متون علمی بررسی میکنیم.
خطای هالوسینیشن(توهم ) در هوش مصنوعی : تعریف و مفهوم
در حوزه مدلهای زبانی بزرگ (LLM)هر پاسخ یا جزئیاتی که مدل با ظاهری قانع کننده ولی فاقد مبنای واقعی تولید میکند، «هالوسینیشن» گفته میشه. این اصطلاح تشبیهی از یک واژه روانپزشکی است ( به معنی توهم دیداری/شنیداری)، امّا در به چه AI معنی هست،چه ویژگی هایی داره و به چه دلایلی این خطا ایجاد میشه.
ویژگیها و دلایل اصلی ایجاد خطای هالوسینیشن"مدلهای LLM":
|
دلایل اصلی ایجاد خطای هالوسینیشن در مدلهای LLM
۱. دادههای آموزشی ناکامل یا قدیمی
مدلهای هوش مصنوعی بر اساس دادههای تاریخی آموزش میبینند. اگر این دادهها ناقص، قدیمی یا حاوی اطلاعات نادرست باشند، مدل ممکن است "خطای هالوسینیشن" تولید کند.
۲. تنظیمات نادرست پارامترها
پارامترهایی مانند "دما (Temperature)" در مدلهایی مثل ChatGPT، وقتی روی مقادیر بالا تنظیم شوند، باعث افزایش خلاقیت مدل میشوند که میتواند منجر به تولید "محتوای ساختگی" شود.
۳. طراحی ضعیف پرامپت
اگر پرامپت ورودی به مدل مبهم، متناقض یا فاقد ساختار مناسب باشد، مدل هوش مصنوعی ممکن است مسیر اشتباهی را طی کرده و "هالوسینیشن" تولید کند.
۴. فشار برای پاسخدهی تحت هر شرایطی
مدلهای هوش مصنوعی طوری طراحی شدهاند که همیشه پاسخی ارائه دهند، حتی وقتی اطلاعات کافی ندارند. این ویژگی ذاتی میتواند دلیل اصلی "خطای هالوسینیشن" باشد.
چرا خطای هالوسینیشن برای نگارش متون علمی خطرناک است؟
در "پژوهشهای علمی"، استفاده از دادههای درست و رفرنسدهی معتبر ضروری است. "خطای هالوسینیشن هوش مصنوعی" میتواند عواقب جدی زیر را داشته باشد:
۱. تولید ارجاعات و منابع جعلی
مدل ممکن است منابع علمی معتبر اما کاملاً ساختگی تولید کند که وجود خارجی ندارند.
۲. تحریف نتایج تحقیقات
ارقام و نتایج آماری نادرست میتوانند مسیر پژوهش را کاملاً منحرف کنند.
۳. آسیب به اعتبار علمی
استفاده ناخواسته از "محتوای ساختگی" میتواند اعتبار پژوهشگر و مؤسسه مربوطه را زیر سؤال ببرد.
۴. اتلاف وقت در بازبینی
تشخیص "خطای هالوسینیشن" برای داوران و خوانندگان زمانبر بوده و روند پژوهشی را کند میکند.
پس برای اینکه بتونیم جلوی تولید محتوای ساختگی توسط مدلهای هوش مصنوعی رو بگیریم باید ببینیم چه کار باید کرد و چه راهکارهایی داریم:
راهکارهای عملی برای رفع "خطای هالوسینیشن" در "پژوهش های علمی":
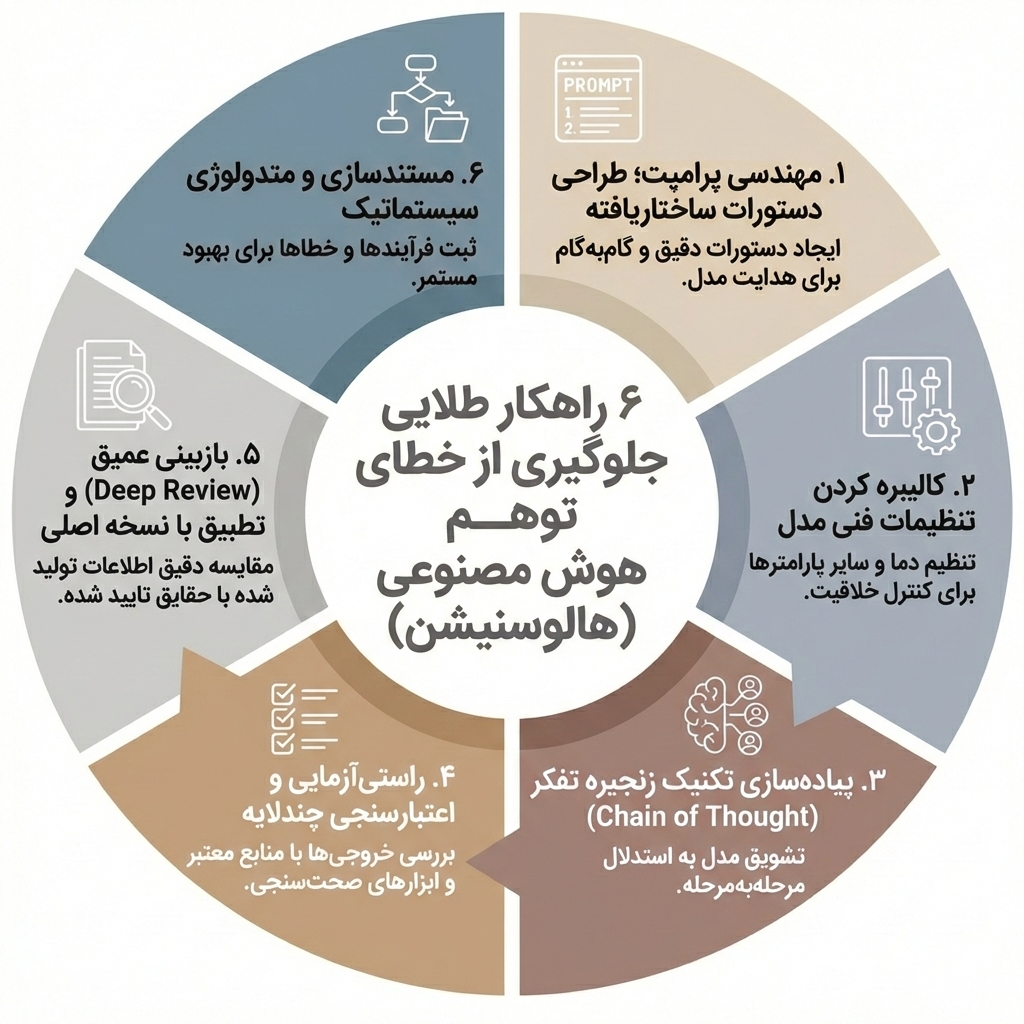
۶ استراتژی برای مهار «توهم هوش مصنوعی» در پژوهشهای علمی
یکی از بزرگترین چالشهای محققان در عصر حاضر، خطای توهم (Hallucination) یا تولید اطلاعات ساختگی توسط مدلهای زبانی بزرگ (LLM) است. برای اینکه پژوهشهای شما از اعتبار علمی ساقط نشود، باید هوشمندانه با هوش مصنوعی تعامل کنید. در ادامه، ۶ راهکار عملی و حرفهای برای کنترل و حذف این خطاها را بررسی میکنیم:
۱. مهندسی پرامپت؛ طراحی دستورات ساختاریافته
دقت خروجی هوش مصنوعی مستقیماً به «ورودی» شما بستگی دارد. به جای دستورات مبهم، از فرمول زیر استفاده کنید:
نقش(به مدل نقش بدهید.) + وظیفه مشخص(دقیقا مشخص کنید چه میخواهید.) + قالب خروجی(مشخص کنید خروجی در چه فرمت و قالبی تولید شود.) + منابع معتبر(از مدل بخواهید برای خروجی تولید شده منبع و رفرنس بدهد.)+از تکنیک Few-Shot استفاده کنید: دادن ۱ یا ۲ مثال از خروجی مطلوب به هوش مصنوعی، احتمال هالوسینیشن را تا ۸۰ درصد کاهش میدهد.
مثال: «به عنوان یک متخصص دیتاساینس، بر اساس مقالات معتبر نمایهشده در PubMed (از ۲۰۲۰ به بعد)، یک چکیده 250 کلمهای درباره هالوسینیشن در LLM بنویس و حتماً DOI منابع را ذکر کن. مثال:.......»
نکته کلیدی در پرامپتنویسی: «همیشه به مدل بگویید: اگر منبعی پیدا نکردی، به جای ساختن آن، بنویس پیدا نکردم.»
پیشنهاد: اگر به دنبال تسلط بر این مهارت هستید، تماشای فیلم آموزش رایگان طراحی پرامپت با متد Chain of Thought را از دست ندهید. (لینک زیر)

۲. کالیبره کردن تنظیمات فنی مدل
برای کارهای حساس پژوهشی، نباید به تنظیمات پیشفرض هوش مصنوعی اکتفا کرد. کنترل پارامترهای زیر الزامی است:
Temperature (دما): این عدد را روی ۰.۳ یا کمتر تنظیم کنید تا مدل از خلاقیت کاسته و بر واقعیت تمرکز کند.
Top-P: برای محدود کردن دامنه کلمات احتمالی و افزایش دقت، این پارامتر را مدیریت کنید.
Seed: جهت دریافت نتایج ثابت و تکرارپذیر در کوئریهای مشابه، از این قابلیت استفاده کنید.
۳. پیادهسازی تکنیک زنجیره تفکر (Chain of Thought)
اجازه ندهید هوش مصنوعی بلافاصله به پاسخ نهایی بپرد! با استفاده از متد CoT، مدل را وادار به استدلال گامبهگام کنید:
پروژه را به زیر-وظایف کوچک تقسیم کنید.
از مدل بخواهید مسیر استدلال (Reasoning) خود را شرح دهد.
صحت هر مرحله را پیش از رفتن به مرحله بعد تایید کنید.

۴. راستیآزمایی و اعتبارسنجی چندلایه
هرگز به ادعای هوش مصنوعی اعتماد ۱۰۰ درصدی نکنید. برای تایید خروجیها از ابزارهای تخصصی کمک بگیرید:
استفاده از Crossref API برای اطمینان از صحت کد DOI.
جستجوی جملات کلیدی در Google Scholar یا Semantic Scholar.
بررسی اعتبار و میزان استنادات منابع با استفاده از پلتفرم Scite.ai.
توجه:
«هوش مصنوعی ممکن است حتی کد DOI را هم جعل کند (هالوسینیشن منبع). پس حتماً لینک را کلیک کنید.»
۵. بازبینی عمیق (Deep Review) و تطبیق با نسخه اصلی
هوش مصنوعی گاهی مفاهیم را به درستی نقل میکند اما در جزئیات دچار لغزش میشود.
اصل منبع را بخوانید: هرگز به خلاصهسازی AI بسنده نکنید.
چک کردن نقلقولها: جملات داخل کوتیشن را با متن اصلی تطبیق دهید.
دقت در افعال: بررسی کنید که آیا AI لحن نویسنده (مثلاً تردید یا قطعیت) را به درستی منتقل کرده است یا خیر.
۶. مستندسازی و متدولوژی سیستماتیک
پژوهش معتبر، پژوهشی است که تکرارپذیر باشد. برای این کار:
تمام پرامپتها، پارامترهای فنی و خروجیهای خام را آرشیو کنید.
از سیستمهای کنترل نسخه مثل Git برای مدیریت تغییرات متن استفاده کنید.
یک «Logbook پژوهش» تهیه کنید تا مسیر رسیدن به نتایج نهایی کاملاً شفاف باشد.
«چک لیست جامع جلوگیری از خطای هالوسنیشن»
مرحله | روش پیشنهادی | ابزار/تکنیک |
طراحی پرامپت | استفاده از داده زمینهای واقعی (citations in → citations out)، تعیین قالب خروجی و درخواست استناد صریح. | Structured prompt + “include DOIs”. |
تولید اولیه | محدودکردن دما (≤0.3) برای کارهای پژوهشی، تقسیم کار به چند گام کوتاه Chain of Thought کنترلشده | Advanced settings در ChatGPT / Claude. |
راستیآزمایی سریع | اجرای پرسش «Source Check» تحت عنوان “list every reference you just relied on with DOI”، تطابق DOI با Crossref یا PubMed | Crossref API, Scite.ai, Consensus. |
بازبینی عمیق | خواندن مقاله اصلی؛ مقایسه نقلقول با متن واقعی، جستوجوی جملات کلیدی برای کشف تحریف یا حذف قیدها. | Full-text search در Zotero, Connected Papers. |
پایش مستمر | ذخیره پرامپتها + خروجی در یک مخزن برای Reproducibility استفاده از ابزارهای آشکارساز خطاFact Score، Reference-Validator. | Git + Markdown logs, Scite Reference Check. |
نکات مهم در استفاده از هوش مصنوعی برای نگارش علمی
1. حفظ نگاه نقادانه؛ فریب اعتمادبهنفس مدل را نخورید.
همیشه نسبت به خروجیها «شکاک» باشید. هوش مصنوعی گاهی با چنان لحن قاطعی اطلاعات غلط را ارائه میدهد که تشخیص توهم (Hallucination) دشوار میشود. هرگز خروجی را بدون بازبینی نهایی در متن پژوهش خود قرار ندهید.
2. استراتژی «تایید متقاطع»؛ ترکیب قدرت مدلها
برای اطمینان از صحت یک تحلیل، یک موضوع واحد را در مدلهای مختلف (مثل ChatGPT، Claude و Gemini) بررسی کنید. نقاط اشتراک این مدلها معمولاً قابل اتکا هستند، اما تفاوتها دقیقاً همان جایی است که باید با دقت بیشتری بررسی کنید.
3. تزریق تخصص (Context Injection)؛ هوش مصنوعی را آموزش دهید.
قبل از شروع کار، اطلاعات کلیدی و چارچوب نظری پژوهش خود را در قالب «زمینه» به مدل ارائه دهید. هرچه هوش مصنوعی با فضای اختصاصی کار شما آشناتر باشد، احتمال تولید محتوای عمومی و غیردقیق کاهش مییابد.
4. پذیرش محدودیتها؛ هوش مصنوعی یک دستیار با هوش است اما تحلیلگر شمایید.
به خاطر داشته باشید که مدلهای فعلی در استدلالهای پیچیده ریاضی، تحلیلهای عمیق انسانی و ارائه دادههای بسیار بهروز محدودیت دارند. هوش مصنوعی سرعت شما را چند برابر میکند، اما «امضای علمی» و تحلیل نهایی باید متعلق به شما باشد.
سؤالات متداول درباره خطای هالوسینیشن
-آیا میتوان کاملاً از خطای هالوسینیشن جلوگیری کرد؟
فعلا با قاطعیت نمیتوان گفت بله، با تکنولوژی فعلی امکان حذف کامل "هالوسینیشن" وجود ندارد، اما در آینده نزدیک شاید. پس بایستی با راهکارهای ارائه شده آن را تا حد زیادی کنترل و مدیریت کرد.
-کدام مدلهای هوش مصنوعی کمتر دچار هالوسینیشن میشوند؟
مدلهای جدیدتر معمولاً در این زمینه بهتر عمل میکنند، اما هیچ مدلی کاملاً مصون نیست. مدلهای تخصصی حوزهای خاص معمولاً عملکرد بهتری دارند.
-چگونه میتوان هالوسینیشن را در متون فارسی تشخیص داد؟
- جستجوی عبارات کلیدی در منابع معتبر فارسی
- بررسی سازگاری تاریخی اطلاعات
- مشورت با متخصصان حوزه مربوطه
- استفاده از ابزارهای بررسی سرقت ادبی
جمعبندی: آینده مدیریت خطای هالوسینیشن
"خطای هالوسینیشن" یکی از مهمترین چالشهای استفاده از "هوش مصنوعی" در "نگارش علمی" است. با پیشرفت تکنولوژی، راهکارهای جدیدی برای مقابله با این مشکل در حال ظهور هستند، از جمله مدلهای راستیآزمای تخصصی، سیستمهای شفافساز تصمیمگیری مدل و استانداردهای جدید برای گزارشدهی استفاده از هوش مصنوعی در پژوهش.
نکته نهایی این است که "هوش مصنوعی" باید به عنوان یک "دستیار پژوهشی" در نظر گرفته شود، نه یک "جایگزین پژوهشگر". مسئولیت نهایی صحت و اعتبار محتوای علمی همچنان بر عهده پژوهشگر انسانی است.
با به کارگیری راهکارهای عملی ارائه شده در این مقاله، میتوانید خطر "خطای هالوسینیشن" را در پروژههای پژوهشی خود به حداقل رسانده و از مزایای "هوش مصنوعی" در "نگارش علمی" بهرهمند شوید.
پیشنهاد: نگارش پایاننامه با ابزارهای هوش مصنوعی نیاز به شناخت نحوه استفاده از هوش مصنوعی در انجام کارهای تحقیقاتی و علمی دارد؛ یک اشتباه کوچک در استناددهی میتواند تمام زحمات شما را از بین ببرد. اگر میخواهید از قدرت هوش مصنوعی در نوشتن پایاننامه خود استفاده کنید اما نمیدانید چگونه خروجیهای آن را علمی و بدون خطا تنظیم کنید، مشاهده «دوره جامع آموزش نوشتن پایاننامه با هوش مصنوعی-صفر تا صد-همراه با پرامپتهای ایجنت محور» را به شما پیشنهاد میکنیم. در این دوره، با طراحی چارچوب نوشتن پایان نامه و ساختاردهی فصول، گرفتن خروجی تمام فصول پایاننامه را خواهید آموخت و میتوانید پایاننامه خود با کمک هوش مصنوعی بنویسید.برای دیدن سرفصلهای دوره به لینک زیر مراجعه کنید.